




Tag drei der Dashboard Week war wieder mit einer neuen Herausforderung gefüllt. Der Tag stand ganz unter dem Zeichen des Web-Scraping. Unsere Aufgabe war es, den Beschreibungstext aus dem Tagesschau-Archiven zu scrapen und daraus eine sinnvolle Visualisierung zu erstellen. Eigentlich relativ simple, oder? Leider nicht. Fünf Stunden, ein komplexer Workflow in Alteryx und das ausprobieren von zahlreichen RegEx-Ausdrücken später hatte ich endlich die Daten, die ich für meine Visualisierung brauchte.
Zum Ende musste ich noch alle Stopwörter rausfiltern und schon hatte ich die von mir gewünschte Datenstruktur.
Mein Ziel war es die Top 10 „Schlagwörter“ aus dem Beschreibungstext der letzten fünf Jahre zu visualisieren. Allerdings waren die „Schlagwörter“ jedes Jahr nah zu identisch welches natürlich nicht das gewünschte Ziel der Visualisierung war. Daher überlegte ich mir noch eine weitere Datenquelle anzubinden.
Ich entschied mich dazu die Top 10 Suchbegriffe von Google mit den Top 10 „Schlagwörtern“ der Tagesschau pro Jahr zu vergleichen. Da die Tagesschau sich primär mit dem politischen Tagesgeschehen auseinandersetzt und Google ein sehr interessanter Indikator dafür ist, was die Gesellschaft im letzten Jahr beschäftigt hat entschied ich mich die Top 10 gegoogelten politische Schlagzeilen als Datenquelle heranzuziehen.
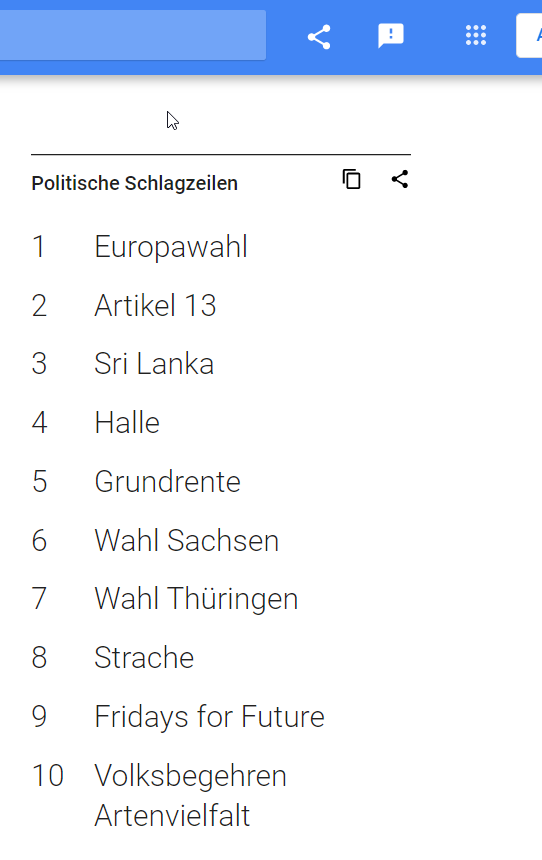
Überraschenderweise gab es nur minimale Übereinstimmungen bei den Top 10 „Schlagwörtern“ der Tagesschau und den Top 10 politischen Schlagzeilen die gegoogelt wurden.
Die Anbindung einer zweiten (externen) Datenquelle ist stehst ein probates Mittel um einen Gesamtüberblick oder einen anderen Blickwinkel über ein Themengebiet zu erhalten.


