




Dies ist ein Blog zu einem Webinar, das hier abgerufen werden kann. Dazu gibt es eine Arbeitsmappe auf Tableau Public, die hier angesehen und heruntergeladen werden kann.
Die Covid-19 Pandemie war und ist für die meisten Menschen ein einschneidender Zustand. Ich merkte sehr früh, dass nicht nur die Maßnahmen meinen Alltag beeinflussten, sondern auch die Berichte und Diskussionen dazu.
Üblicherweise lese ich mehrmals pro Tag Nachrichten in diversen Online-Zeitungen, darunter Spiegel Online. Es fiel mir auf, dass es immer und immer mehr Berichte über das neue Coronavirus gab, während über andere Themen kaum noch geschrieben wurde. Selbst wenn ein Thema diskutiert wurde, war immer irgendein teilweise auch konstruierter Bezug zu Corona vorhanden. Da Nachrichten meine Wahrnehmung der Ereignisse auf der Welt stark beeinflussen, war ich nach einer kurzen Zeit überwältigt und genervt von dem starken Fokus auf dieses eine Thema.
Das führte mich dazu, diese Wahrnehmung anhand von Daten zu überprüfen. Daher entschied ich mich, die auf Spiegel Online veröffentlichten Nachrichten daraufhin zu überprüfen, ob sie von „Corona“ handeln oder nicht und wie der Anteil an allen Artikeln sich entwickelte.
Mithilfe von Alteryx konnte ich einfach alle Nachrichten eines Tages aus dem Nachrichtenarchiv herunterladen: https://www.spiegel.de/nachrichtenarchiv/.
Aus den heruntergeladenen Daten kann man einfach den Link des tatsächlichen Artikels herausziehen. Dieser wiederum kann dann ebenfalls heruntergeladen werden.
Diesen Vorgang durchlief ich für alle Tage bis zurück zum 01.12.2019, um einen möglichst kompletten Zeitraum analysieren zu können. Am Ende stand ein Datensatz mit allen ca. 15.000 veröffentlichten Nachrichten-Artikeln (ausschließlich bento und Manager-Magazin) vom 01.12.2019 bis 19.04.2020.
Das ermöglichte es mir, ebenfalls in Alteryx diese Texte auszuwerten und daraufhin zu überprüfen, ob verschiedene Begriffe, die ich mit Covid-19 verband, in den Titeln und / oder Artikeln vorkamen. Damit wurde eine Kategorisierung möglich.
Diese kategorisierten Artikel konnte ich dann in Tableau visualisieren und mit den berichteten Neuinfektionen und Todesfällen in Beziehung setzen. Meine Hypothese dabei war, dass eine steigende Zahl von Infektionen & Toten das Interesse verstärkt und damit den Anteil der Artikel über Corona erhöht.
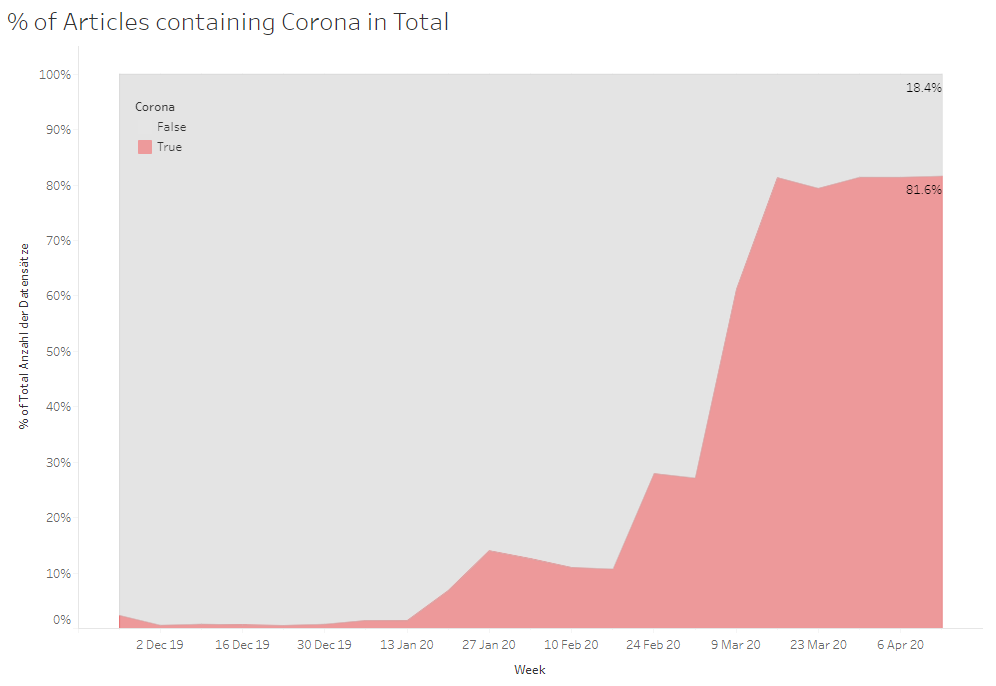
Die Auswertungen waren für mich sehr spannend. So kam heraus, dass fast 80% der Artikel am Ende des beobachteten Zeitraums in irgendeiner Art und Weise Keywords zum Thema Corona enthielten!
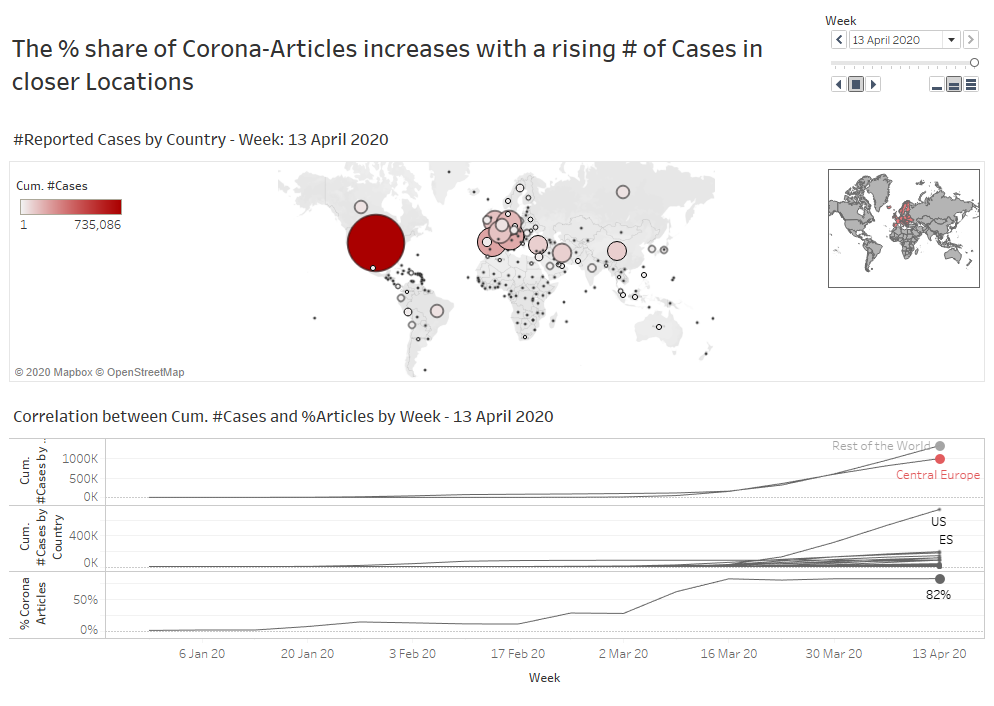
Außerdem scheint das Interesse deutlich größer zu sein, wenn Fälle in der unmittelbaren Nähe stattfinden. Frühe Fälle in China hatten weniger Einfluss auf den Anstieg der Artikel als die Ausbreitung in Italien oder Spanien. Meine Hypothese konnte also nicht verworfen werden, dafür konnte ich aber weitere spannende Insights generieren.
Schlussendlich sollte nicht vergessen werden, die Qualität der Daten und das Vorgehen allgemein anzusprechen. Grundsätzlich ist sogenanntes „Web-Scraping“ mindestens eine Grauzone. Da der Spiegel aber eine Historie mit solchen Auswertungen hat, ging ich einmal großzügig von einer Duldung aus. Bezüglich der Datenqualität muss gesagt werden, dass die Artikel unterschiedliche Textstrukturen in den Websites aufweisen und daher nicht sichergestellt werden kann, dass überall nur die korrekten Textinformationen ausgelesen wurden. Auch die Auswahl der überprüften Keywords war willkürlich und nur von meinem Verständnis geleitet. Für mich war aber der übergreifende Trend wichtig, wofür die Daten meines Erachtens gut genug waren.


