




Was haben die Finanzwirtschaft, die Ökonomie, Meteorologie und die Polemologie gemeinsam? Börsenkurse, Arbeitslosenquoten, Temperaturentwicklungen und dyadische Konflikte lassen sich allesamt mithilfe von Zeitreihen analysieren. Ein Ziel der Zeitreihenanalyse ist es, basierend auf historischen Entwicklungen Prognosen über den zukünftigen Verlauf einer numerischen Größe treffen zu können. Aber was ist genau eine Zeitreihe?
Definition einer Zeitreihe
Für die Definition einer Zeitreihe verwende ich die Definition von statista. Sie ist demnach eine zeitlich geordnete Folge statistischer Maßzahlen. Die Reihenfolge dieser Maßzahlen ergibt sich ausschließlich aus der zeitlichen Abfolge ihres Auftretens.
Ein Beispiel für eine solche Zeitreihe ist die Entwicklung des S&P 500. Diese kann man sich auf der Internetseite der Federal Reserve Bank von St. Louis herunterladen.
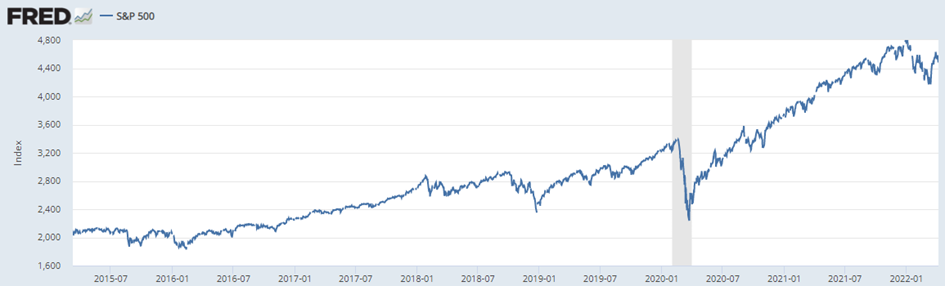
In dem folgenden Abschnitt bereite ich die Daten so auf, dass man sie als Zeitreihe verwenden kann. Diesen Schritt beziehe ich in diesen Blog ein, weil viele Zeitreihen eine Data Preperation benötigen, damit sie für eine Analyse verwendbar werden.
Datenvorbereitung
Zu Beginn der Datenvorbereitung müssen wir uns einen Überblick über die Daten verschaffen. Nach dem Download kommen die Daten in Alteryx wie folgt an:
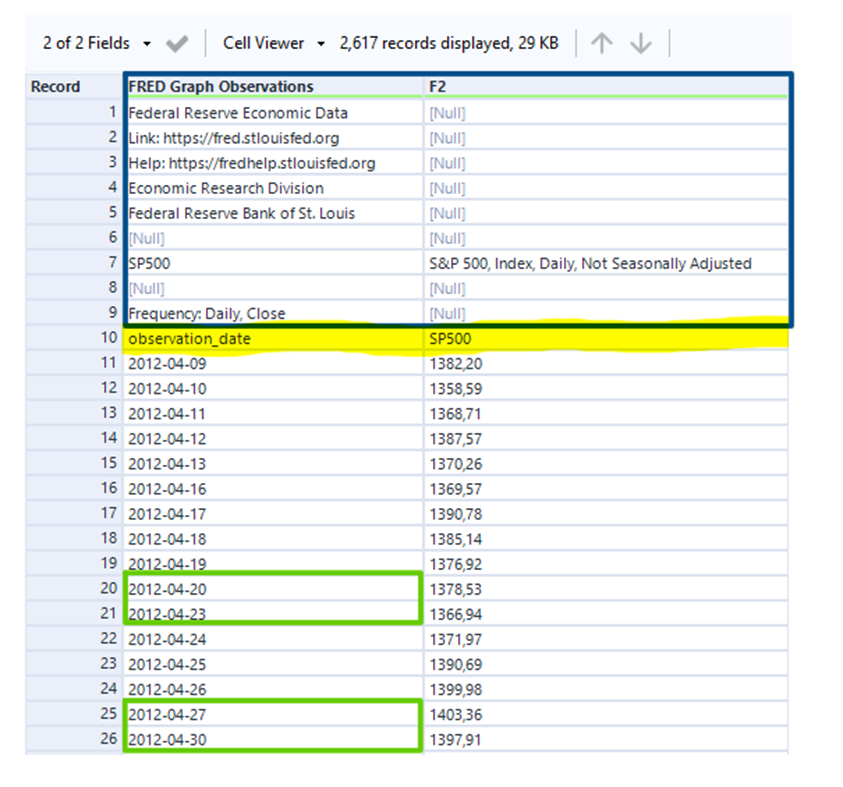
Die Spaltenüberschrift scheint sich in der zehnten Zeile zu befinden. Erst ab der elften Zeile beginnt dann die eigentliche Zeitreihe. Die grünen Rechtecke markieren Zeitpunkte an denen es regelmäßige Sprünge im Datensatz gibt. Manchmal kann das bei der Modellierung zu Problemen führen. Daher werden wir im Laufe der Datenvorbereitung diese Lücken mit den entsprechenden Datumsdaten füllen.
Wie sieht es mit den Datentypen beider Spalten aus?

Da es in beiden Spalten nicht nur Datumsdaten und numerische Daten gibt, sondern auch Metainformationen vorhanden sind, wird der Datentyp auf Strings gesetzt.
Diese Beobachtungen führen zu vier Schritte in der Datenvorbereitung:
1. Entfernen der ersten neun Zeilen
Für das entfernen von Zeilen in Alteryx bieten sich prinzipiell zwei Tools an: Das Filter Tool, das Zeilen basierend auf Bedingungen filtert, und das Sample Tool. Für unseren Fall eignet sich das Sample Tool.
Workflow:

Input:

Output:

2. Die Zelleninhalte der zehnten Zeile als Überschrift verwenden
Wir haben uns von den ersten neun Zeilen des Datensatzes getrennt, Cool! Jetzt können wir damit fortfahren, die Spaltenüberschriften aus Zellen der ersten Zeile der Tabelle zu extrahieren. Dafür eignet sich das Dynamic Rename Tool.
Workflow:
Input:
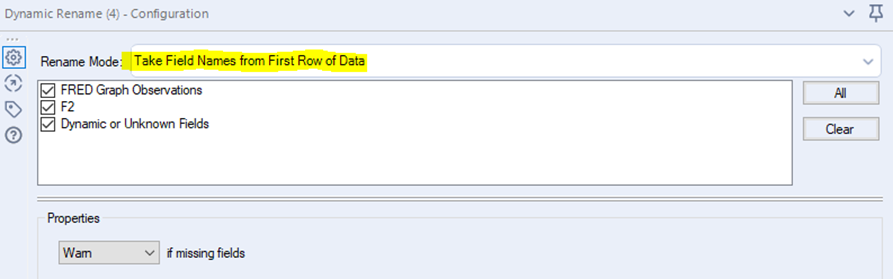
Output:
Es ist wichtig darauf zu achten, dass man beim Rename Mode im Konfigurationsfenster „Take Field Names from First Row of Data“ auswählt. Der Output sieht aber schon mehr nach einer Zeitreihe aus, mit der man arbeiten kann.
3. Die Datentypen ändern
Für die Änderung von Datentypen kann man das Select-Tool wählen. Dieses kann man auch für die Umbenennung von Spalten und das Entfernen von Spalten nutzen.
Workflow:

Input:

Den Datentyp „Double“ kann man neben dem Datentypen „Float“ in Alteryx für Dezimalzahlen nutzen.
Output:

Dir sollte aufgefallen sein, dass der Output für die Spalte „SP500“ nur ganze Zahlen ausgibt, obwohl wir den Datentyp „Double“ gewählt haben. Das liegt daran, dass Alteryx den Punkt als Dezimaltrennzeichen verwendet und nicht das Komma. Gäbe es doch nur eine Möglichkeit das Komma durch einen Punkt zu ersetzen. Zum Glück gibt es das Formel Tool, das uns die Manipulation von Spalten ermöglicht. Dieses setzten wir in unser Workflow zwischen dem Dynamic Rename und Select Tool ein.
Workflow:

Input:

Wir wählen als „Output Column“ die bereits existierende Spalte „SP500“. Eine Alternative wäre es, eine neue Spalte zu erstellen. Das hätte den Vorteil, dass ich den Datentyp der ausgegebenen Spalte im Bereich „Data type“ frei wählen könnte. Jedoch müsste ich dann im Anschluss die alte Spalte entfernen.
Die „ReplaceChar“-Funktion hat drei Parameter: Die Spalte von Interesse, ein Satzzeichen, das getauscht werden soll und ein Satzzeichen, das das erste Satzzeichen ersetzen soll. Diese Funktion kann man nur auf Spalten vom Datentyp String anwenden. Da wir im Workflow das Select Tool, das wir zur Veränderung des Datentyps nutzen, erst hinter dem Formel Tool platziert haben, sollte das kein Problem darstellen.
Output:

Jetzt haben wir unsere Datentypen angepasst und können zum letzten Schritt unserer Datenvorbereitung übergehen.
4. Die Datumslücken füllen
In diesem Schritt verwenden wir zum ersten mal ein Tool aus der Time Series Tool Palette. Das TS Filler Tool identifiziert Lücken in einem Datensatz und füllt diese Zeilen auf. Die Zeitreihen Tools wurden mit der Programmiersprache R erstellt, daher sieht man das Symbol auch im Design der Tools.
Workflow:

Input:

Wir wählen eine Spalte in unserem Datensatz, die den Datentyp „Date“ oder „DateTime“ hat. Dann stellen wir das Intervall ein, in dem die Datumsdaten vorliegen und entscheiden uns für ein Inkrement.
Output:

Das TS Filler Tool gibt noch zwei weitere Spalten aus. „OriginalDateTime“ transformiert die ursprüngliche Spalte in ein DateTime-Format und füllt die Zeilen mit Nulls, die ursprünglich nicht in der Tabelle waren. „FlagGeneratedRow“ nimmt für alle Zeilen, die in der ursprünglichen Tabelle bereits vorhanden waren, den Wert „False“ und für die Zeilen, die neu hinzukommen, den Wert „True“ an.
Da wir „OriginalDateTime“ und „FlagGeneratedRow“ nicht mehr verwenden, entferne ich sie aus der Tabelle mit einem Select Tool.
Workflow:
Input:

Output:

Mit diesem Output können wir nun unsere ersten Modelle erstellen.
In Teil 2 dieses Blogs erfahrt ihr, wie man mittels der von Alteryx zur Verfügung gestellten Zeitreihen Tools verschiedene Modelle erstellt, verschiedene Modelle miteinander vergleicht, Prognosen erstellt und diese auf ihre Präzision überprüft.


